
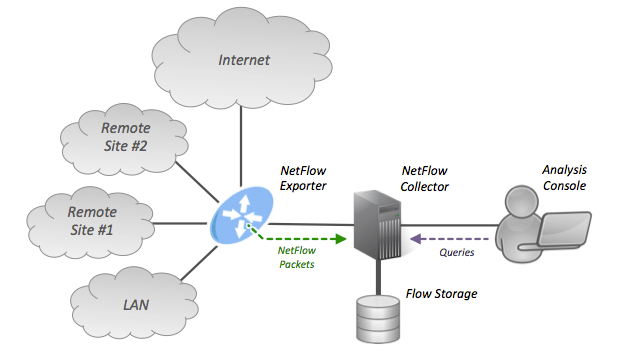
When choosing a network traffic analyzer NetFlow is one of the most widely used standards due to its versatility, robustness, and speed. By definition, “NetFlow is a network protocol system created by Cisco that collects active IP network traffic as it flows in or out of an interface. The NetFlow data is then analyzed to create a picture of network traffic flow and volume.”
For this reason, it was the basis of the network intrusion detection system (NIDS) which Allata developed as part of a larger cybersecurity initiative taken by one of our customers.
Brute Force Attacks
According to Verizon’s 2020 Data Breach Investigations Report, hacking remains the primary attack vector. Over 80% of breaches caused by hacking involve Brute Force attacks, or the use of lost or stolen credentials.

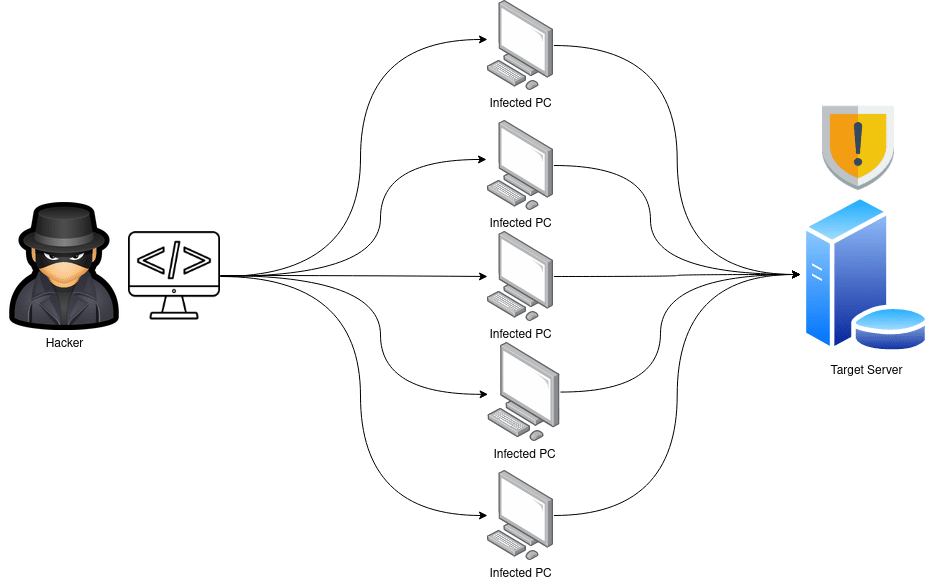
DDoS Attacks
Between January 2020 and March 2021:
increase in Number of ddos Attacks
55%
attacks using multiple vectors
54%
attacks targeting the tech sector
27%
The increment in the quantity and the complexity of attacks, is pushing the limits of detection systems, forcing the engineers to use even more sophisticated techniques rather than the typical strategy based on blacklists/whitelists of IP addresses. Here is where Machine Learning takes part, bringing us automated detection capabilities and at the same time being able to find unique patterns within malign data flows.
Introduction
During the development of the Network Intrusion Detection System (NIDS) via Machine Learning we faced a few challenges, one of them was the generation of a well-balanced dataset with enough information to train a model with high accuracy but, at the same time, avoiding undesirable overfitting.
In order to avoid overfitting, we have at least two main alternatives. The first one is during the model training phase: the number of iterations (training steps), hyperparameters values, learning rate, and model topology will define the model behavior over new events to be inferred (unseen data). The second one (covered in this post) is the creation of a well-balanced dataset (without one-feature preponderance) with enough and diverse data to allow the model to learn detection patterns aiming at high accuracy and robustness during the validation phase.
Using public datasets
As any good data scientist knows, data quality and variety are one of the key aspects in every Machine Learning development. The final result is directly related to the quality of the data used. In other words, garbage-in garbage out. Within the domain of NetFlow network attacks there are only a few and well-known public datasets (NSL-KDD dataset, KDDCUP-99, NF–UQ–NIDS) which have a large number of events (+9M) but the cons of not being updated (in the case of KDD CUP – 1999) or being well balanced (mostly benign data). These constraints are what pushed us to look for other data sources for the training dataset elaboration.
The need of synthetic data
The creation of data in a controlled environment allows obtaining beforehand a clear understanding of the desired results. In the project, the need arises due to the lack of labeled data as well as traffic on a specific Port or with a certain pattern in order to strengthen the model during the training phase. Another important point is the need for a well-balanced dataset, it means that all the classes or labels must have the same number of events to avoid bias in the AI model. Another option that might be considered, apart from synthetic data generation, is data augmentation over the existing public data, in other words, make random modifications to generate new different data and thus to achieve a more varied and comprehensive dataset.
For our case, this technique is not possible due to the complex nature of network attacks, any modification in a given network event could mean a reduction in the detection capability of the model. Therefore, the creation of synthetic data is the only way to guarantee a training phase with quality data.
Creating and capturing synthetic network data
We chose 4 main network traffic categories to be detected by the model: Benign, Brute Force, DoS, and DDoS. For the generation of malicious Brute Force traffic, we chose to use a SSH Brute Forcer tool. This tool generates both benign and malicious SSH traffic. The proportion of each type of traffic is set during the initial configuration. SSH Brute Forcer can generate a specific amount of traffic over TCP/IP port 22 (SSH) which allows the model to learn with high accuracy how to detect these attacks.
To generate malicious DoS and DDoS traffic we chose the Magic Wand tool, and in the same way as with SSH Brute Forcer, we can specify the desired amount of traffic (malicious and benign) as well as the type of attack to generate (there are many classes within DoS and DDoS attack main categories).
Finally, to run both traffic generators we recommend using a Docker image to avoid creating local dependencies and to guarantee greater control over the data generation pipeline. Inside the Docker image, a network traffic analyzer like Tshark was needed to capture the generated data into a .pcap file.
Format conversion
The output file generated by the network traffic analyzer contains all the logs or events produced by the traffic generators in .pcap format. Although this format contains all the raw data of the captured logs, for our purpose a conversion to NetFlow traffic format is necessary. For this not-so-easy engineering task, we designed a Docker container, capable of transforming the .pcap format input file into a NetFlow format output file.
The script also allowed us to add a data pre-processing stage into the pipeline, leaving only the most relevant features for traffic analysis as well as incorporating feature engineering techniques: generating reliable and accurate data to feed the machine learning model.
Data pipeline
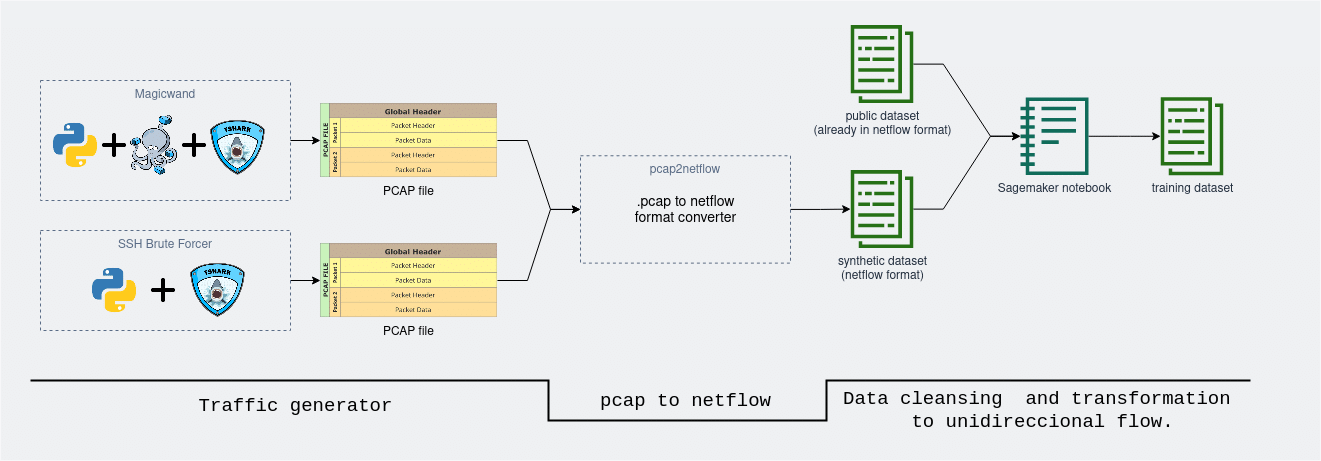
After covering the implementation of all the main data stages it is time to connect and integrate all the building blocks into a single functional system. In the image below there is a high level overview of the pipeline design.
In the first “traffic generator” stage the network traffic is generated and captured. At this stage, the input variables are the proportions, amount, and type of traffic desired while at the output a raw file with all the generated events is obtained. In the second “format conversion” stage, the raw .pcap format log file is transformed into a standardized NetFlow format. Also, a cleansing and feature engineering pre-processing stage is incorporated.
Finally, in the last “data cleansing and transformation” stage, the synthetic data is added to the existing public data to then be ingested in a new pre-processing stage where cleaning, mapping, variable casting, etc. tasks are taken over. The output file is the final dataset we use for model training and validation.
Final thoughts
The generation of synthetic data is a complex key task for the development of any Machine Learning project. All imbalances or deviations from the real data will result in a bias or negative impact on the precision of the model to be trained. Therefore, during the validation phase, it is necessary to use techniques that guarantee that the addition of synthetic data affects positively the behavior of the model. Techniques such as cross-validation or custom weighted metrics will be covered in future posts.
The ability to generate quality labeled data on-demand allows us to train a Machine Learning model with high accuracy and robustness. It also opens up new opportunities, such as the design of a retraining pipeline in which the model can be constantly updated, adapting to the needs or changes in the patterns of the network communications.
During the development of the Network Intrusion Detection System, the preparation of the training dataset was one of the many tasks that our engineering team had to solve. Due to confidentiality issues, many important details involved in these efforts are not covered in this post but if you are interested in any additional technical aspects or implementing similar solutions, feel free to reach us out! In Allata we are ready to discuss any potential projects and solutions.


