
Generative AI and Intelligent Document Processing
Generative AI is revolutionizing document-heavy industries by transforming manual, error-prone processes into efficient, intelligent workflows. By integrating intelligent document processing (IDP) with generative AI, organizations can convert unstructured data into actionable insights—achieving outcomes like lower costs, faster processing, and more informed decision-making.
Amazon Bedrock is a fully managed service that aggregates top foundation models from leaders like Anthropic, AI21 Labs, Cohere, Meta, Stability AI, Mistral AI, and Amazon. With a single secure API, Bedrock empowers businesses to leverage advanced AI models at scale, reducing manual labor, mitigating errors, and ensuring compliance across complex document workflows.
In this post, we’re going to dive into a sample IDP solution that extracts critical data from a scanned handwritten form filled out by people applying for birth certificates. We’re using Anthropic’s Claude 3 Sonnet model on Amazon Bedrock, which is highly leveraged by enterprise users and is known for its speed, efficiency, and advanced vision capabilities—including the interpretation of photos, charts, graphs, and technical diagrams. Although our demonstration focuses on Claude 3 Sonnet, alternative models such as Haiku or Opus can easily be swapped in, since we’re using Bedrock.
Next, we break down the technical architecture—from data ingestion and model selection to precise extraction workflows and database integration—illustrating how generative AI drives productivity improvements, cost reductions, and faster time-to-insight.
Solution Breakdown: Data Extraction
Use Case and Dataset
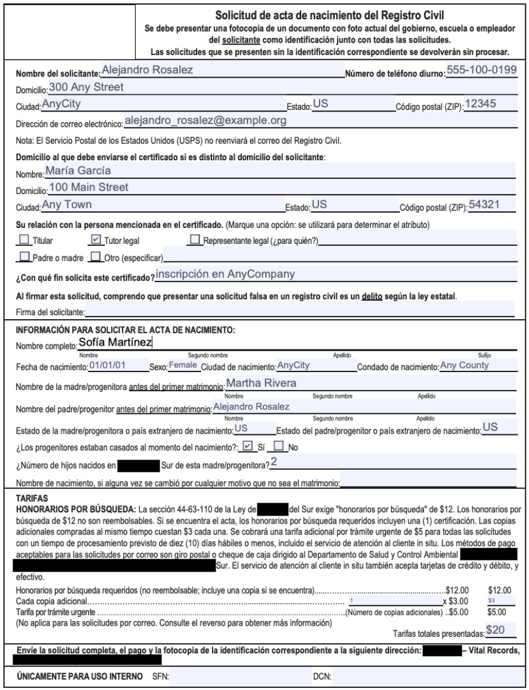
Our example centers on a state agency that issues birth certificates and receives applications via multiple channels—online submissions, in-person forms, and mailed paper applications. Traditionally, processing these forms involves scanning, manually extracting details, and entering data into an application that stores the information in a database. This approach is time-consuming, inefficient, and prone to errors. The challenge intensifies when forms are in different languages, such as Spanish.
For this solution, the data set that we can use to prove its value is as simple as two scanned images of birth certificate application forms. This use case is intended to support multiple languages and varying layouts, so those requirements should be taken into consideration when coming up with the sample data set.
- An English handwritten form
- A Spanish printed form

Prompt Engineering
Prompt engineering is key to unlocking the full potential of generative AI in IDP. Crafting precise prompts ensures outputs are accurate, relevant, and aligned with your objectives while reducing variability and risk.
With Anthropic Claude 3 integrated into Amazon Bedrock, you leverage advanced visual understanding to extract data directly from documents. Provide an image or document as input, and Claude 3 interprets its contents—extracting and returning the desired information in a human-readable format. The model supports multiple languages, enabling tasks like translating Spanish forms into English using targeted prompt instructions.
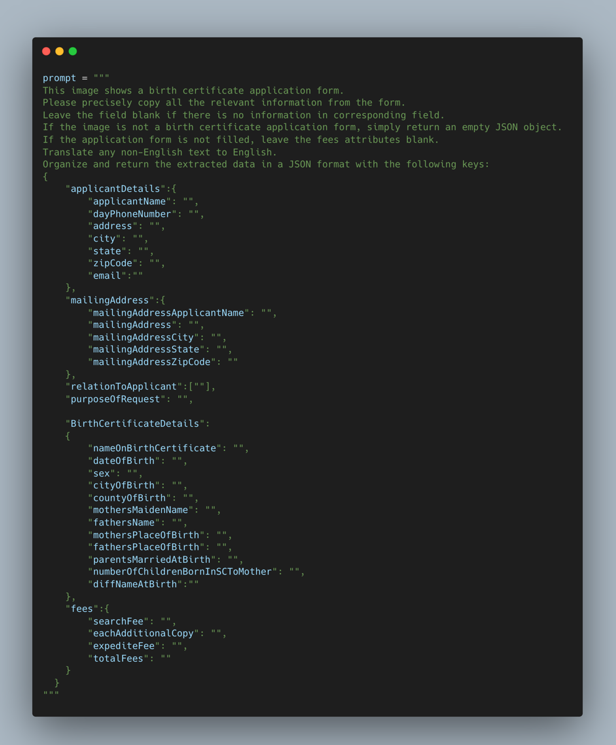
Because response formats can vary, it’s essential to tailor prompts for consistent, structured output. For example, instruct the model to return data in JSON with predefined keys. This approach simplifies integration with downstream applications and streamlines your data processing workflows.
Below is an example prompt specifying the desired JSON output format:
Cloud Architecture
This solution is cloud-native and serverless, so you’re essentially only paying for it when you use it. It’s also fully deployable as infrastructure-as-code (IaC), so there’s very little operational overhead around deploying it.
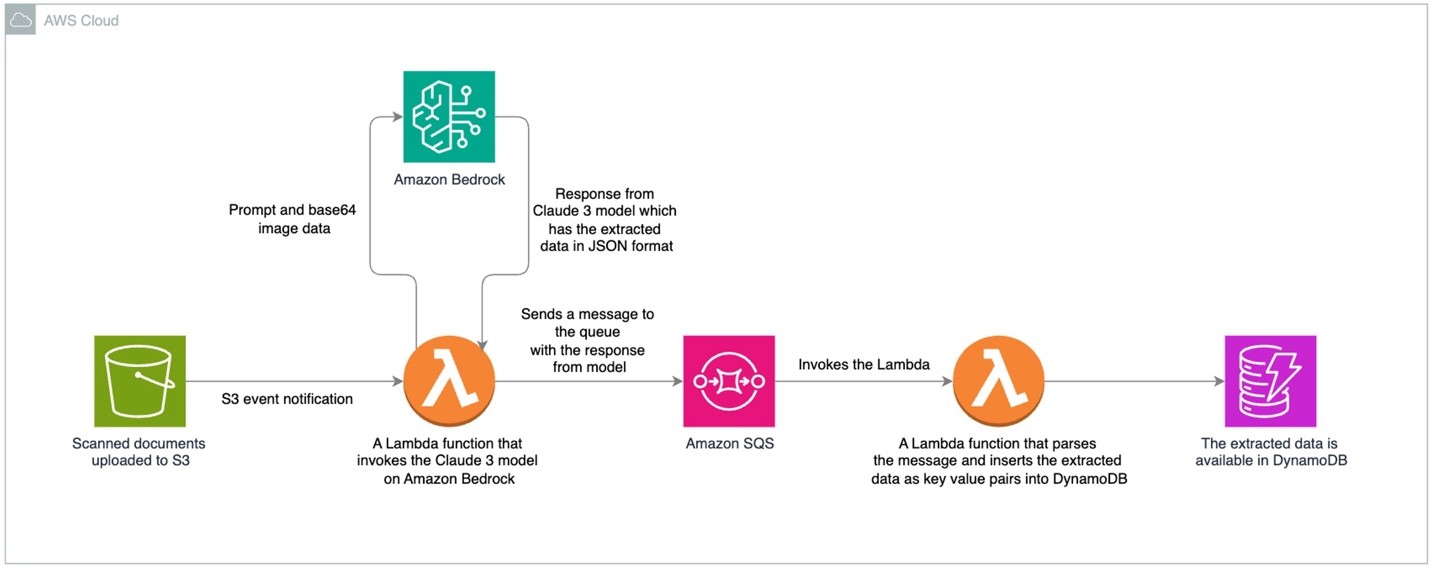
Our solution leverages a suite of AWS services seamlessly integrated with Amazon Bedrock to extract data from scanned documents. Here’s how the entire process flows, from the input dataset to the final structured output:
- Data Ingestion (Dataset Entry): Scanned documents (our sample dataset, such as the English handwritten and Spanish printed birth certificate forms) are uploaded into an Amazon S3 bucket. This bucket triggers an event notification whenever a new file is added, ensuring the process starts automatically.
- Initial Processing (Prompt Execution): The S3 event triggers an AWS Lambda function, which is tasked with invoking the Anthropic Claude 3 Sonnet model on Amazon Bedrock. At this stage, the prompt—crafted during our prompt engineering phase—is passed to the model. This prompt guides the model on how to extract the relevant information and, in cases like Spanish forms, even translate data into English.
- Data Extraction (Model Processing): The Anthropic Claude 3 Sonnet model processes the input image using its advanced multimodal capabilities. The model extracts the desired details and returns them in a structured JSON format, following the format we specified in our prompt.
- Message Queuing: The extracted JSON data is sent to an Amazon Simple Queue Service (Amazon SQS) queue. SQS acts as a buffer, decoupling the model output from the subsequent processing, ensuring the system remains scalable and fault-tolerant.
- Final Data Storage: A second Lambda function picks up messages from the SQS queue. This function parses the JSON and stores the key-value pairs in an Amazon DynamoDB table, making the extracted data available for further analysis or integration with downstream systems.
Key Services:
- Amazon S3: Think of S3 as your digital filing cabinet—storing all your scanned documents safely and in an organized way, ready to be picked up whenever needed.
- AWS Lambda: Lambda is like a nimble, on-call assistant who springs into action as soon as a new document lands in S3—no clocking in required.
- Amazon Bedrock (with Anthropic Claude 3 Sonnet): Picture Bedrock as the brainpower hub. Here, the Anthropic Claude 3 Sonnet model acts like a master detective, meticulously analyzing and extracting the essential details from your documents, just as a skilled translator would.
- Amazon SQS: SQS functions like a reliable post office, queuing up messages (data) and ensuring they’re delivered in order, so nothing gets lost in transit.
- Amazon DynamoDB: DynamoDB is your digital notebook, where all the extracted insights are neatly recorded and easily accessible for future reference.
Picture the final experience – A user logs into a web app and uploads a scanned document—or even emails an attachment or has a bulk scanner push files to S3—initiating a seamless process. Immediately, a Lambda function picks up the file and sends it to Anthropic Claude 3 on Amazon Bedrock, where the document is rapidly analyzed and transformed into structured data. Within seconds, that data is queued, processed, and stored in DynamoDB, making it instantly available for an employee to review on their dashboard.
This architecture, built on serverless components, is designed for scalability and cost-effectiveness. It streamlines the document processing workflow—from the moment the dataset enters S3 to when the extracted data is stored in DynamoDB—while incorporating the prompt engineering insights that drive accurate, structured outputs.
For production-scale deployments, you may incorporate in a few more elements, such as human-in-the-loop validation, model evaluation, and improved exception handling, to handle edge cases and optimize performance.
Conducting Your own Similar POC is Simple
Does this spark a few ideas for you around how it could be applied in your company’s operations? The good news is that the prerequisites for a proof-of-concept like this are minimal. All you need is:
- An AWS account with an IAM user who has permissions to DynamoDB, Lambda, Amazon Bedrock, Amazon S3, Amazon SQS, and IAM.
- Access to Anthropic Claude 3 Sonnet or an equivalent model which can be managed easily via Amazon Bedrock.
- Test data like the sample birth certificate application forms, which can be used to validate the proof of concept.
- A defined use case which can be as simple as Given X (data set), I can Y (perform a function) so that Z (business outcome).
With these basic requirements, you can successfully complete a similar Proof of Concept (POC) at your company to clarify ROI or gain buy-in to operationalize IDP in core business processes.
We’re All In on AI
You might be thinking, “We already use tools like Textract or ABBYY Flexicapture—what’s different here?” The exciting part is that these new foundation models deliver far greater accuracy and simplify implementation dramatically. Instead of needing a full team of ML engineers spending months on a POC, you can build a compelling proof-of-concept in just weeks with one or two developers.
If you’d like to explore how this approach can transform your document processing or simply want to pick our brain about AI, please get in touch. We’re here to help you navigate your AI journey.


