
Traditionally, data pipelines ran batches in Hadoop clusters. It could be done on premise, within your own infrastructure, or in the cloud, for example, by consuming AWS EC2 or GCP Compute Engine resources.
Hadoop comes in as many flavors as there are vendors. Just to mention a few of them:
And finally, the top Cloud providers, Google and AWS:
Cluster setup is becoming obsolete because new analytic pipelines are running in Serverless mode.
What does that mean? It doesn’t strictly mean that there are no servers. When the code is running, you of course need a server to run it on.
The main difference with Serverless architectures is that, where before you had to preemptively setup the needed infrastructure (cpu, memory, disk, etc), now your code runs no matter which infrastructure is behind the process. Your cloud provider takes care of providing the required infrastructure and you pay only for the costs of the code you execute on it. Architecture is often used for real time data processing. AWS Lambda and AWS Kinesis are good examples of this.
This makes it seem like EMR is an obsolete tool for running batch processes under pre-provisioned infrastructure, and that AWS Lambda is the replacement tool for running real time computation in a serverless architecture, right? Well… that is partially correct or partially incorrect, depending on whether you choose to see the glass as half empty or half full.
On one hand,
On the other hand,
But, a great complement for EMR is the AWS Data Pipeline Tool. Thanks to AWS Data Pipeline we can run EMR Batch processes on a schedule, in a serverless architecture.
That is not the only purpose of AWS Data Pipeline, though. It also allows us to connect all the dots (EMR, Lambda, S3, RDS, Glue, SNS, etc) that we referred to at the beginning of this post, in a simple and straightforward way, thanks to its intuitive graphical user interface.
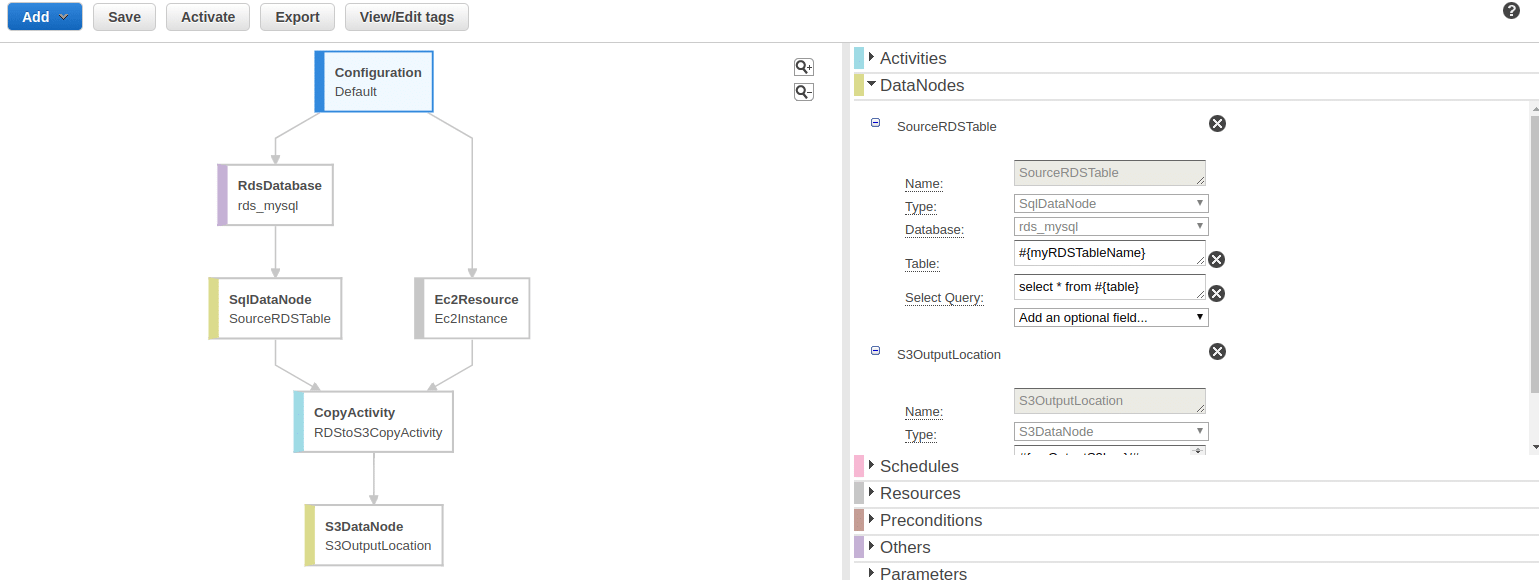
We encourage you to surf the official AWS Data Pipeline document site, as well as Edureka’s free educational content on YouTube.


