Introduction
When users interact with websites or apps they generate a lot of valuable data composed of their interactions with the items on the page, interaction with other users, and demographic data such as age, gender, etc. Interaction data itself can be composed of different actions made by the user such as clicks, likes, ratings, comments, time spent, etc. All that data can be used to enhance the user experience, client engagement, retention rate, visit frequency, and purchase frequency -depending on the business case-.
To extract valuable insights from the data to then take decisions there are many tools available like statistical analysis, rule-based triggers, and what this blog covers: recommendations systems based on AI, which is one of the most frequently used solutions to suggest relevant items to the users based on the choices they make.
For this solution, AWS offers a specific service: Personalize which is introduced as follows: “Personalize enables developers to build applications with the same machine learning (ML) technology used by Amazon.com for real-time personalized recommendations”. That means for us a ready-to-deploy service that can be easily integrated into the AWS cloud ecosystem.
In Allata we tested the service in order to evaluate the performance and characteristics claimed by AWS.
Recipe selection
In AWS Personalize, a recipe means algorithms that are prepared for specific use cases, based on common solutions. Every recipe has predefined attributes for the data, algorithms, feature transformations, and initial parameters for the training phase as well as a set of API requirements. As expected, there are many recipes gathered by 4 main categories: USER_PERSONALIZATION, PERSONALIZED_RANKING, RELATED_ITEMS, and USER_SEGMENTATION. Each of the categories contains different recipes optimized for different use cases, available data, and recommendation goals.
Defining the use case
Before the selection of the best-suited recipe, we need to define our use case. For this test, we’re going to create a recommendation system for News with the goal of giving to every user a set of items (news) suited to their latest interactions or, in more practical words, the news more likely to be visited by the user.
Choosing a recipe
For our specific use case, we choose the USER_PERSONALIZATION recipe type. This recipe allows us to predict items that the user will interact with based on interactions, items and Users datasets, enabling personalized recommendations for each of the users.
Data preparation and schema definition
Choosing a dataset
To test Personalize the MIND dataset was used. This large-scale and well-known dataset was collected from anonymized users behavior logs of the Microsoft News website. MIND is generally used as a benchmark dataset for news recommendations thus it perfectly fits with our needs.
The dataset is composed of 2 sub-datasets: one for the user behaviors such as the click histories and impression logs and the other for the information or metadata of news articles (items).
Formatting and feature selection
As with any other data science project, a significant part of the total work is spent on data cleaning and transformation tasks. AWS provides us a guide for the input data formatting, defining the required fields, format, data type, length limitations and even the formatting for explicit impressions.
With the user interactions dataset, we ended up leaving 5 features including the impressions that are all the elements that were shown to the user when the event was recorded.
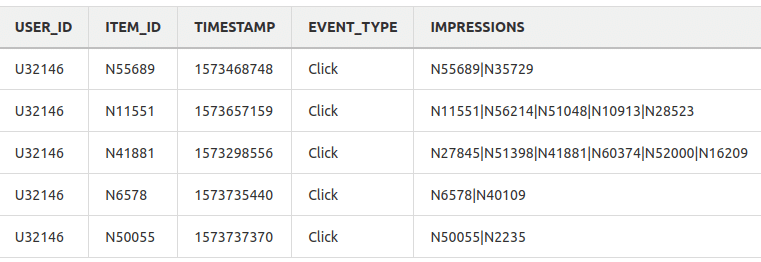
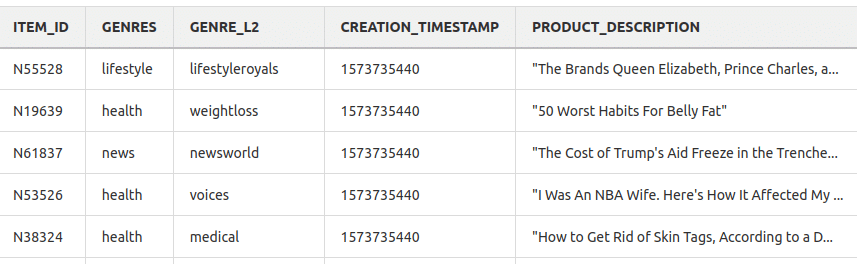
The items dataset required more cleaning tasks compared to the interactions dataset. Five features are what the dataset is finally composed of, including the main genre and sub-genre columns. Timestamp was not provided by the dataset but is a required field for Personalize, in order to solve this problem, we use the interaction dataset timestamp for that particular event. Finally, an unstructured feature: product description.
Using unstructured data
When using a Machine Learning Recommendation system we’re often limited by the input data type to 2 main types: Categorical and Numerical, both structured data types. If we want to extract value from unstructured data like text, a lot of extra steps are required, including language treatment techniques such as Bag of Words, stop words cleaning, vectorization, etc.
With Personalize, AWS is going a step beyond including all these transformations in-built into the service allowing us to use unstructured data types directly without prior treatment.
Using Natural Language Processing, AWS Personalize can extract meaningful information from text such as product descriptions, product reviews or movie synopses to then identify relevant items for users, particularly when items are new or have fewer interactions data.
In our use case, we added the News title as an unstructured feature.
Creating a dataset schema
For Personalize a schema defines the structure of the data allowing the service to parse the data. The schema is a JSON file in Avro format which includes relevant information such as the dataset name, input type, name of the fields and their respective data type and the version. The number and name of the fields must be equal to the ones used in the dataset.

For Personalize a schema defines the structure of the data allowing the service to parse the data. The schema is a JSON file in Avro format which includes relevant information such as the dataset name, input type, name of the fields and their respective data type and the version. The number and name of the fields must be equal to the ones used in the dataset.
Training a solution and deploying a campaign
After the data preparation and recipe selection, the next step is to create a Solution. This term is used by AWS Personalize to refer to the combination of a Recipe, customized parameters and one or more solutions versions (trained models). Finally, we create a campaign to deploy the solution version and get recommendations.
To create a solution we do the following steps:
- Configure a solution: Customize the solution parameters and recipe hyperparameters
- Creation of a solution version: Train the machine learning model
- Solution version evaluation: Use the metrics AWS Personalize generates from the solution version to evaluate the performance of the model.
The process of creating a solution version took several minutes to complete. The training time is directly related to the dataset size and features types (use of unstructured data may increase the time considerably)
Training modes
When training a solution version, AWS Personalize gives us 2 types of training modes: FULL and UPDATE. The full mode is suited when we trained for the first time the model or when we decide to re-train the model with the whole dataset (including the data that has changed compared to the initial dataset) whereas the update mode is when we want to update incrementally the solution but only using the data that has been changed or added.
Creating a campaign
A campaign is a deployed solution version (trained model) with provisioned dedicated transaction capacity for creating real-time recommendations via API operations. If we instead decide to get recommendations in batch mode, then a campaign is no longer necessary.
Due to the campaign being the link between the machine learning model and the user request it needs to be capable of processing the stream loads of recommendations, in other words, set the needed resources that allow the service to be executed without delay or loss of transactions. To manage this, AWS Personalize lets us set a minimum provisioned TPS (Transactions Per Second) parameter while creating a campaign. If the demand exceeds the set minProvisionedTPS, Personalize can auto-scale the capacity up and down (never below the min TPS). Depending on the min TPS value will be the service cost, so the tuning of this parameter is a key point to keep in mind.
Getting and analyzing recommendations
Recommendations can be get in real-time or in batch mode. In our case of study, we are going to focus on real-time events. With the chosen recipe, only the GetRecommendations API operation is available.
There are three ways to get recommendations: with the Amazon Personalize console, AWS Command Line Interface (AWS CLI), or AWS SDKs. GetRecommendations needs a userId or a sessionId value – in case the user is not logged in (an anonymous user). AWS Personalize allows us also to define and use contextual metadata to get recommendations, this data can be, for example, the DEVICE in which the API operation is requested; taking into account contextual metadata should provide a better recommendation.
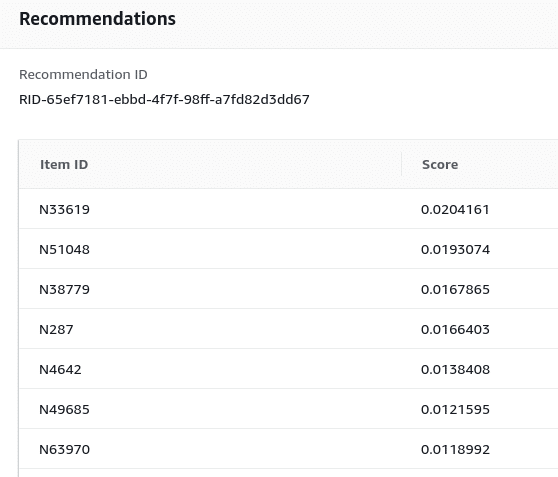
The response of the API contains the requested number of top recommendations (default value: 25) and the score for each one. These scores represent the relative certainty that Amazon Personalize has in which item the user will select next. Higher scores represent greater certainty.
For all the available regions, AWS allows us to connect programmatically to the service using an EndPoint. The EndPoint name changes depending on the AWS region, but the protocol remains the same for each one: HTTPS.
Keeping datasets and recommendations current
Recommendation systems need to be updated with some frequency: users’ interactions and preferences change over time as well the items catalog. In our case, the News business is constantly changing depending on the relevant topics of the day: during the labor week, economics News are highly demanded whereas, on weekends, lifestyle or entertainment news are the most requested. AWS Personalize takes into account the existence of these variations, offering us ways to update the interactions and items dataset and to update the trained model to be in line with the latest version of the dataset without any service interruption.
Updating the datasets and their impact
For real-time recommendations AWS allows us to keep the interactions dataset up to date with the users’ behavior by recording interaction events with an event tracker and the PutEvents API operation. This operation can record up to 10 interaction or impression events.
For an already trained model, the new records influence immediately the next recommendations, allowing us to mitigate the cold-start issue, a characteristic problem of the recommendation system when the dataset lacks enough data for a given user, to return good recommendations.
If we want to update the items dataset, AWS provides us with a different API operation: PutItems. In this case, using the User-personalization recipe AWS Personalize automatically updates the model every two hours. After each update, the new items can be included in recommendations. This operation can be manually operated if the default two hours window is not frequent enough: we need to create a solution version with trainingMode set to UPDATE to include those new items in recommendations.
What is a new or incognito user?
When a new or incognito (without userId) user interacts the first time with items we need to record those events using the PutEvents API operation, but due there is not enough historical data for the user when we call the GetRecommendations API the response recommendations will initially be for popular items only.
For anonymous users (user without a userId), AWS Personalize uses the sessionId we pass in the PutEvents API operation to associate events with the user before they log in. This creates a continuous event history that includes events that occurred when the user was anonymous.
Amazon Personalize stores the new user data and will include the user when the service updates the recommender or when we manually train a new solution version.
Note:
The sessionId is a required field to get a recommendation. This value must be generated for every user, in the case of an incognito user we can use cookies to create and store a sessionId.
Hyperparameters tuning and filters definition
As with any other machine learning system, AWS Personalize includes hyperparameters to allow the user to tune the behavior of the model while training or making predictions.
To set the model training hyperparameters we need to use solutionConfig when creating the Solution to override the default parameters of a recipe. If the performAutoML parameter is true, all parameters of the solutionConfig object are ignored. The allowed parameters to tune are:
Tuning these parameters requires certain knowledge and experience in Machine Learning, that’s why AWS Personalize incorporates an extra parameter to the solutionConfig: performHPO. Hyperparameter optimization (HPO) is an automatic optimization technique to choose the optimal hyperparameters for a specific learning objective. For our example, we use the default parameters, but it’s good to know that if the behavior of the system is not the expected we can tune it to match the requirements.
Another set of hyperparameters can be defined in the campaign configuration. The benefit of these parameters is that can be tuned after the model training with only a campaign update, which means no extra re-training cost and time. The parameters allowed to be tuned are:
We set the exploration_weight to 0.5; a compromise between a conservative model and a model that decides to suggest items with any or no interactions. The exploration_item_age_cut_off was set to 7 meaning that only items of the past 7 days since the last interaction are going to be considered by the model.
Output filters
Apart from hyperparameter tuning, it is also possible to add a specific filter to the output of the model. This took great relevance when we need to make sure that the recommendations meet certain criteria or restrictions, for example, for child users we can create a filter to avoid recommending News not appropriated for underage people. Another example of filtering is not recommending News already seen by the user.
All these filters can be created using SQL-like expressions, then when calling the GetRecomendations operation we need to specify the filter parameter to be used.
Required cloud services and cost analysis
There is a minimum set of required AWS services to run AWS Personalize and start getting recommendations:
Note:
It’s important to set up or update the AWS IAM role and policy to grant the correct access between all the needed services.
Service cost
The cost of running the service will be according to three main factors: the size of the datasets, the number of recommendations needed per second (TPS), and the number of FULL-mode model training per week.
These factors are related to the case of use and the needs of the service customer. In our case, as it was just a test of the AWS Personalize service, no analysis cost was made but, for reference, AWS brings us a few examples of pricing here.
The number of re-training depends on the frequency of updates for new items and users; if we have a great number of new users per week, or the number of interactions recorded per user meets a certain threshold then a re-train will be more frequent.
The same criteria apply to the calculation of the min TPS value. Because of the auto-scalability characteristic of the service, we can define a low TPS to then run the service and, using AWS CloudWatch, define the optimal TPS value for our application.
Conclusions
After testing the service with a real use case and diving into the AWS Personalize service options and solutions available to create recommendation systems, we can conclude that AWS has created a really good service with great out-of-the-box performance for a wide variety of use cases.
Using AWS Personalize we don’t have the necessity of creating a machine learning recommendation system from scratch while the integration with other AWS cloud services is pretty straightforward and that is a very important factor when we need to solve real-world problems without spending too much time on R&D.
Some of the features to highlight are: the capacity to process unstructured data types using NLP to extract meaningful characteristics, auto-scalable endpoints to match the variable service load, capacity to update the recommendations based on the newly recorded user interactions without a full-retraining, and the ability to filter the output by custom filter expressions.
Despite the performance of the service with the default settings being ok, we think that a more detailed tuning of the hyperparameters before and after the training of the model should be needed to fit completely the customer requirements and their use case.
AWS Personalize is just one of the many services required to create an end-to-end complete solution, and here in Allata, we have the expertise and knowledge in applied AI to solve customer needs such as NLP, ML, and many other custom solutions as well as the integration with cloud services.
If you are interested in the implementation of similar solutions feel free to reach us out!
At Allata we are ready to discuss any potential projects and solutions.
References


