
Introduction
From autonomous vehicles to personalized recommendation systems, AI has proven to be a game-changer for businesses worldwide. Within the realm of AI, Generative AI stands out as a fascinating field with the ability to generate data and enhance business processes. There has been an explosion of research on how to effectively harness and build around Generative AI in the past few months, and one thing has emerged as being critical to its success: To harness the power of Generative AI effectively, organizations must address the crucial challenge of acquiring the correct data at the right time to be able to feed the model effectively.
While many strategies are emerging for how best to bring data to the AI models, in our research, there has been a clear winning pattern and approach. By using Data Products as part of a Data Mesh approach to harnessing your data, you can bridge between raw data sources and AI models, facilitating the delivery of organized and consumable data without integrating your AI solutions into your organization in a highly complex and brittle way. Leveraging a Data Product approach beyond Generative AI has many other clear benefits. Still, AI and ML solutions are separated from the concerns of getting quality data. They can focus on just delivering business value.
In this article, we will explore the significance of obtaining the right data at the right time for Generative AI. We will delve into the importance of data quality, timeliness, and relevancy in achieving optimal performance. We’ll begin by introducing the concept of Data Products and the Data Mesh paradigm, highlighting their role in delivering high-quality data to Generative AI models. Ultimately, we’ll examine some real-world scenarios and showcase how organizations can successfully overcome data acquisition challenges and achieve remarkable results.
The Importance of Getting the Right Data at the Right Time
Generative AI holds an enticing promise for businesses, creating entirely new realities and possibilities for efficiency and growth. However, the success of these systems hinges significantly on one crucial factor: data. Not just any data but data that is contextual and surfaced in a timely manner.
First and foremost, why is data so crucial to Generative AI? The power of these systems lies in their ability to learn from patterns and mimic them, creating new data that closely aligns with what they’ve learned. However, as with any learning process, the quality and relevance of what is being taught significantly impact the outcomes.
Feeding inadequate or outdated data to the language models can lead to unsatisfactory, irrelevant, or even erroneous results. Imagine teaching a child solely using obsolete textbooks. While the child may learn something, much of the knowledge will be antiquated and not applicable to current contexts.
Timely data is also a crucial factor in the equation. In today’s fast-paced digital landscape, data can quickly become obsolete. A Generative AI must continually receive and learn from the most recent and up-to-date data to produce the most relevant and accurate results.
Quality, relevance, and timeliness form the trifecta of data attributes crucial in achieving optimal Generative AI performance. Therefore, the challenge of obtaining the right data at the right time becomes paramount. However, it’s a challenge that’s easier said than done. It requires robust strategies and sophisticated tools to ensure data flow is seamless, updated, and of the highest quality.
Two key concepts, Data Products, and Data Mesh, serve as these much-needed tools in the quest for quality data for Generative AI models as demonstrated in Figure 1. They promise to make the challenge of data acquisition less daunting and more streamlined, paving the way for success in the age of AI.
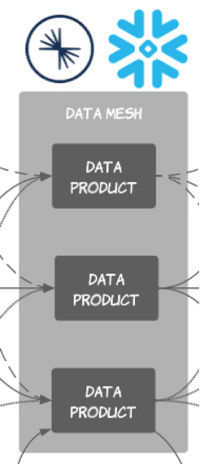
Introducing Data Products and Data Mesh
Navigating the complex and dynamic landscapes of data acquisition for Generative AI models can be daunting for businesses. Thankfully, concepts and tools such as Data Products and Data Mesh are game-changers in this regard.
Data Products, in simple terms for this article, can be described as data organized in a format that can be readily consumed. They streamline raw data, transforming it into a structured, consistent, and usable form. When applied in the context of Generative AI, they ensure that the models are supplied with high-quality and relevant data, which is necessary for optimal performance.
On the other hand, Data Mesh can be seen as a transformative approach to data architecture and management. It is essentially a decentralized approach that places the onus of data management and governance in the hands of the teams that use the data. This approach breaks away from the traditional siloed and centralized data handling methods, thereby reducing bottlenecks and increasing efficiency.
The symbiosis between Data Products and Data Mesh paves the way for a new era of data handling. Data Products ensure the delivery of quality data, and Data Mesh ensures that data is managed and governed effectively. These concepts flip the traditional data management methods on their heads. They propose that instead of having a single team handling the vast streams of data, it should be the responsibility of various groups across the organization, each managing its own subset of data, thereby creating a mesh-like structure.
By decentralizing data management and promoting data product creation, organizations can ensure they leverage quality, timely, and relevant data in their AI applications. It transforms the cumbersome data acquisition process into a smooth, manageable, and efficient system, paving the way for businesses to harness the power of Generative AI truly.
Overcoming Challenges in Data Ingress Modalities
Having introduced the concepts of Data Products and Data Mesh, let’s delve into a significant aspect of data delivery for Generative AI models – data ingress modalities. In understanding the nature of these modalities, their associated challenges, and ways to overcome them, we can better harness the power of Generative AI.
Data ingress, the method by which data enters a system, can take several forms. Each modality comes with its own challenges that can hinder the flow of high-quality, relevant, and timely data.
One such modality is streaming, which deals with real time data ingestion and processing. This modality allows for the most recent data to feed into AI systems. Yet it poses challenges, such as dealing with a sudden influx of data, which may overwhelm the system, or ensuring that data processing keeps pace with data ingestion.
API or point-to-point modality, another data ingress method, has limitations. While it allows for direct, controlled data transfer, it can create potential bottlenecks, mainly when dealing with a large volume of data from multiple sources.
The batch modality, which involves aggregating and uploading data in groups at scheduled times, also has its hurdles. These include data synchronization and latency issues, which can impede the timely acquisition and utilization of data.
The beauty of incorporating Data Products and Data Mesh in dealing with these data ingress challenges lies in their inherent properties. Data Products provide an organized, structured form of data that can streamline real time ingestion in the streaming modality, minimize bottlenecks in the API modality, and aid in more efficient data synchronization in the batch modality.
On the other hand, Data Mesh, with its decentralized approach, can foster agile, autonomous teams that are better equipped to handle and resolve data ingress challenges quickly and efficiently instead of relying on a single, central data management team.
Leveraging Data Products and Data Mesh for Optimal Data Flow
Now that we’ve navigated the challenges of data ingress modalities let’s focus on how the strategic utilization of Data Products and Data Mesh can facilitate optimal data flow, propelling Generative AI to its full potential.
Data Products, which provide a streamlined and structured form of data, are instrumental in making data readily consumable by Generative AI models. However, the mere creation of data products is not enough. An effective governance system must oversee the process to ensure the data’s quality and relevance. Incorporating data governance, along with data cataloging and standardized interfaces, can enhance data product development, guaranteeing that the right data is available at the right time.
Similarly, with its decentralized structure, the adoption of Data Mesh offers a unique approach to managing and delivering these data products. With this system, instead of the traditional top-down management of data, individual teams across an organization share the responsibility. Each team manages its subset of data, ensuring faster resolution of data issues and the ability to update and control their data in real time.
This decentralized, or federated, architecture also fosters an environment of self-serve access to data products. This means teams can access the needed data without unnecessary delays or bureaucracy, leading to more efficient operations and enhanced AI outcomes.
Combining these elements optimizes data flow and presents a robust foundation upon which organizations can build their Generative AI applications. But how does this all come together in real-world scenarios? In the next section, we will dive into how we at Allata have been using Data Products to fuel our AI solutions for ourselves and our clients.
Case Study in Generative AI
At Allata, we’ve built several AI-enabled tools and created AI solutions for our clients. Let’s focus on one tool that helps our sales teams at Allata: AllataBot. AllataBot is a tool we’ve built using Microsoft’s Semantic Kernel and various interfaces that users can interact with.
For those who aren’t as familiar, Semantic Kernel provides a robust framework in which we can build AI plugins and capabilities that can be invoked via an API in a semantic context. See Figure 2 for how we conceptually use the Semantic Kernel in our AI accelerator.
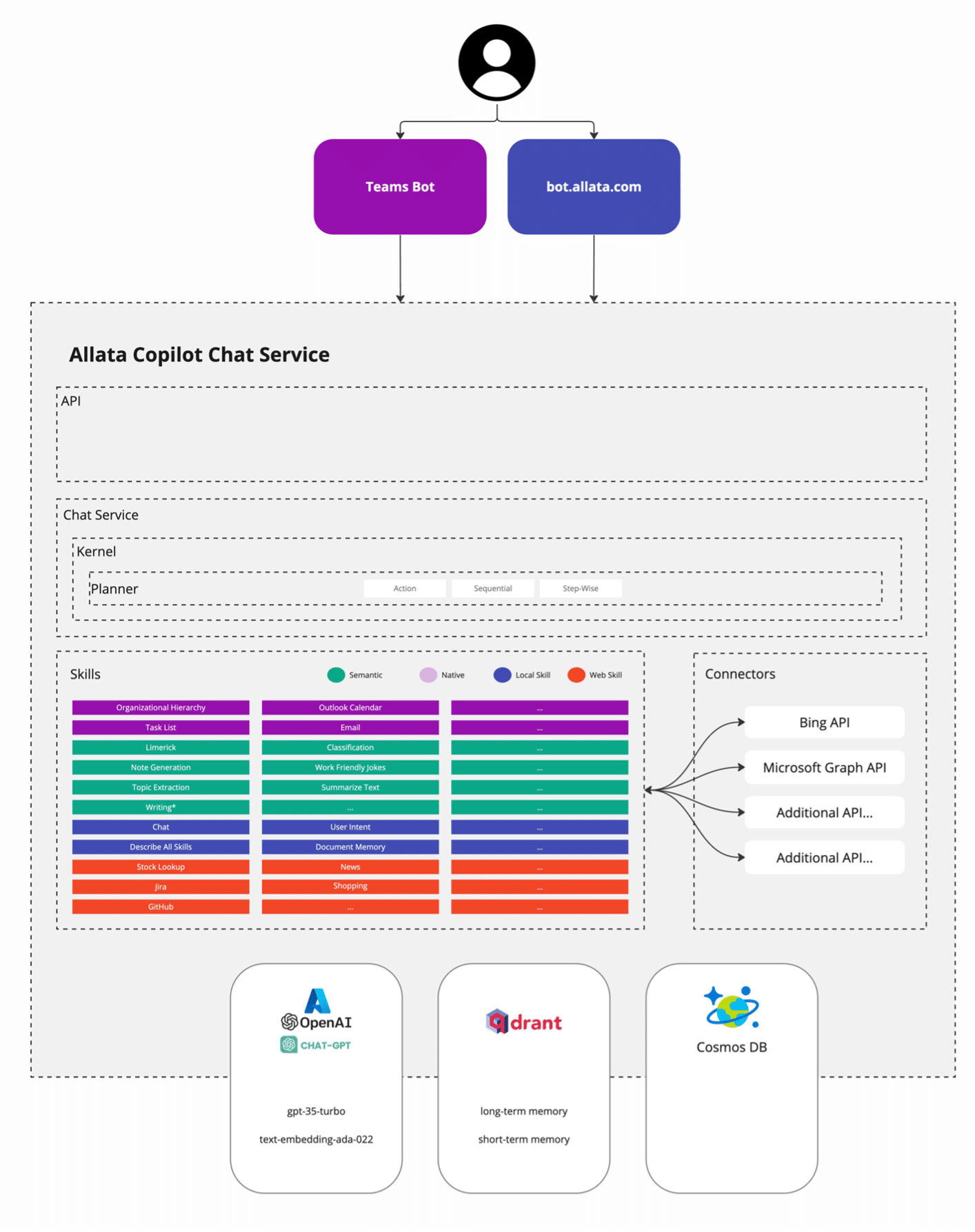
One challenge we have as a consultancy is ensuring that our sales teams and service offering leads have good information about our prospects, their industry, and what context we’re engaging with them in. Combining AI and Data Products with an intuitive UI/UX significantly reduces the time needed to gather this information.
Technically speaking, we built a Data Mesh Accelerator, an opinionated framework we’ve developed at Allata to build out Data Products. These Data Products are a combination of Confluent’s fully managed Kafka service, kSQLDB, and .NET Microservices, all deployed in either AWS or Azure with the help of Terraform. The Data Products are fed data from various sources, internal and external to Allata, while AI plugins from our Semantic Kernel endpoint enrich the data.
In real time, we can enrich the AI-generated output by uploading additional information that is translated into various embeddings and stored in a vector DB for short-term and long-term memory. All of this is surfaced through a UI, so users don’t have to worry about having open-ended conversations with a chatbot, and we can invoke just the plugins and skills we need on the AI solution.
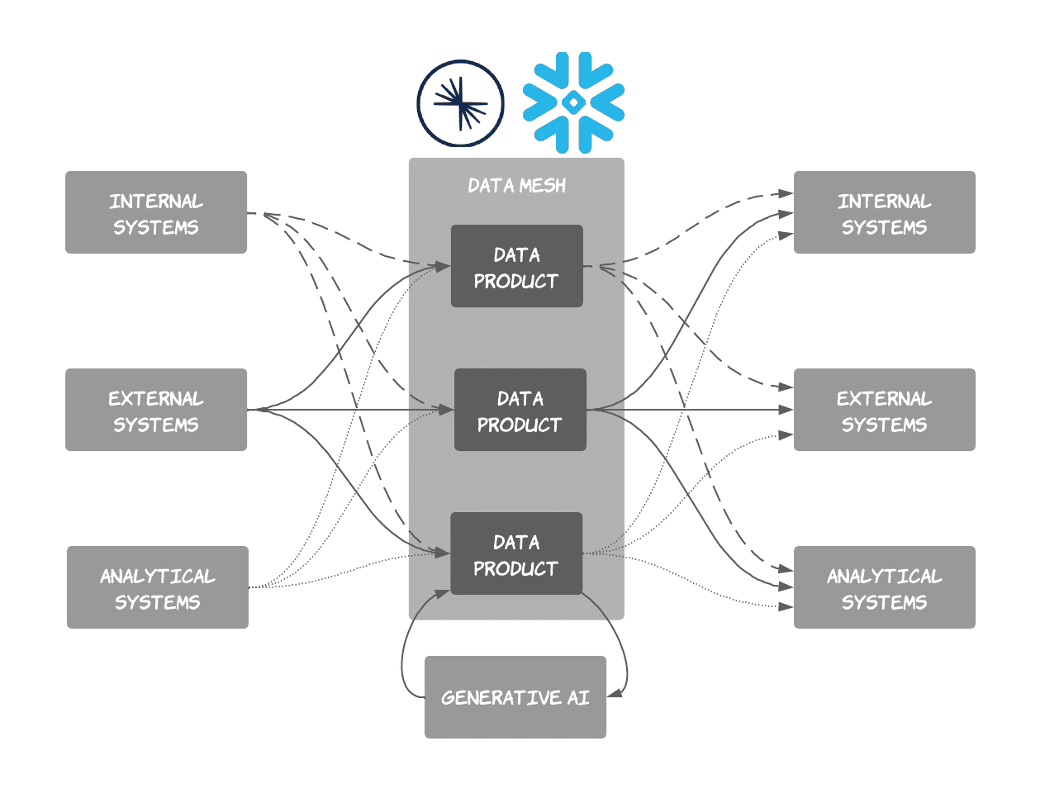
This approach works remarkably well. Our Data Mesh Accelerator saves us multiple weeks when building out Data Products on either Confluent’s data streaming platform or Snowflake. We use these high-quality Data Products in our AI solution by enriching the data as part of the Data Product or as part of the context window for the model invocation. See Figure 3 and 4 for a quick view of how we logically fit it all together.
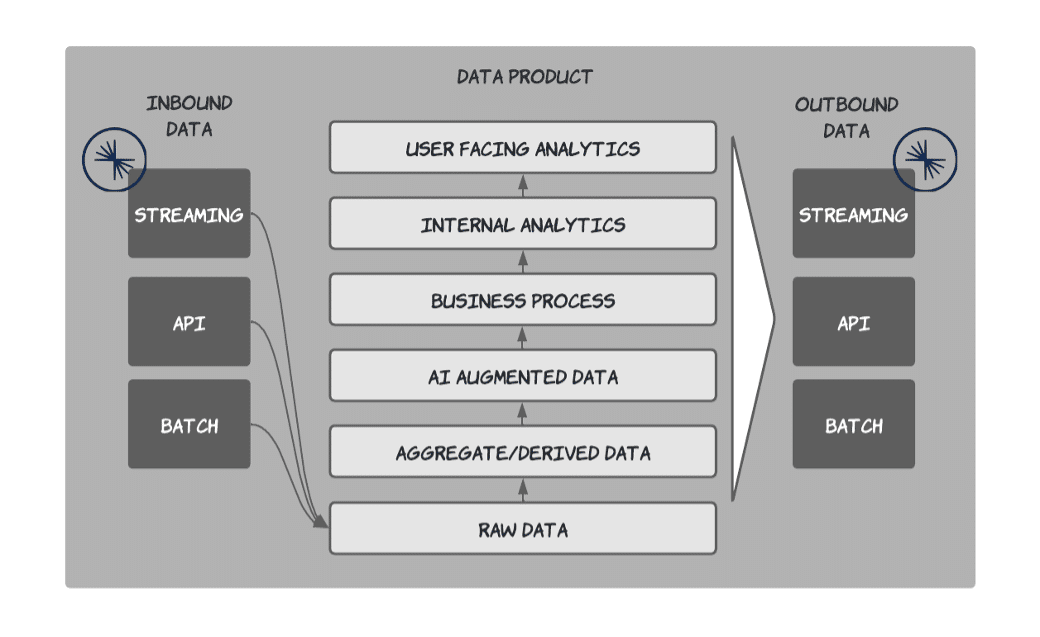
Wrapping it all up
Through this exploration of the importance of obtaining high-speed, quality data for Generative AI, it becomes evident that effective data management is not just an advantage; it’s a necessity. The complex nature of data acquisition and handling can be significantly simplified by leveraging innovative tools and strategies such as Data Products and the Data Mesh paradigm.
Data Products transform raw, unorganized data into a structured, consistent, and usable form that Generative AI models can readily consume. Simultaneously, implementing a Data Mesh approach allows for decentralized data governance that is both efficient and scalable.
The relationship between these concepts presents a fundamentally transformative approach to data management, facilitating access to high-quality, relevant, and timely data. This, in turn, can vastly improve the performance and output of Generative AI applications, driving business growth and innovation.


