
Since then, big data has fragmented in new and interesting ways. As a result, businesses have moved to large data lake applications that store transactions, leads, customer information, product info, inventory, etc., to deal with the rapid increase of enterprise data.
However, companies with a large number of applications have hit a point where it has become difficult for them to get a solid view of their data. As businesses produce and consume more information, the lack of prompt and efficient data accessibility can lead to missed opportunities and even paralyze business growth.
An event-driven architecture, specifically event sourcing, can make data synchronization between the increasing amount of data and applications more manageable and affordable.
The Challenge – More Data, More Applications, More Complexity
Modern data landscapes are large and messy. As a consequence, companies with multiple enterprise applications face the following issues:
Multiple Data Sources and Tedious Data Maintenance
Companies are no longer in an environment where data comes from a single source. They use combinations of systems across their technology landscape. For example, a business could use a Content Management System (CMS) and a Customer Relationship Management (CRM) application. Additionally, it might have a Point of Sale (POS) system or an e-Commerce application integrated with a legacy Enterprise Resource Planning (ERP) system.
As the number of data sources increases, it becomes more challenging to maintain the sources of truth (the system with the correct information on a product, event, or customer). It could create a situation where:
- System A is the customer data source of truth
- System B is the employee data source of truth
- System C is the product data source of truth
- System D adds additional data for all sources of truth!
Cross-referencing all these data sources requires time and effort.
Application, Interface, and Data Synchronization Complexity
When companies are dealing with multiple applications, the various systems have to share and link data. To make this happen, software engineering teams build intermediate applications to map systems to each other. The intermediate applications work as a bridge between the data sources, but at a cost.
Suppose you have five data sources, and you built an application for each source. If you need four configurations for each application, you can end up with 20 different variations, which is a lot of overhead. Moreover, if you want to keep all the data in sync, the number and size of these applications keep growing.
Additionally, you might need to build a REST endpoint for each app that allows other applications to read or interact with the data. This process is highly repetitive because it requires making a unique endpoint for each app. In addition, you will have to maintain those endpoints.
You could leverage a data lake to consolidate the data. However, those are difficult to keep up to date, and it makes real-time data access challenging. In the past, we’ve turned to monolithic databases that are manually populated and synchronized, but this exacerbates existing access, governance, and synchronization issues.
In summary, the most significant problems that we run into with these architectures are that they create slow data pipelines, fail easily, require tedious configuration changes to handle changing workloads, and tight coupling communication exists between the systems.
Finding a Solution with Event-Driven Architecture and Event Sourcing
Event-driven architecture directly solves these issues. It creates highly resilient systems that operate in smart clusters. It communicates seamlessly between large numbers of applications through standardized loosely coupled pipelines. It easily handles wildly varying amounts of work with no required configuration changes or forewarning.
Software engineers and system designers no longer need to obsess over large data lakes of static data. Instead, they view data in motion. So, when they need to keep customer data up to date, they do not care how many applications are working on the data. They only keep track of the changes via the most up-to-date information.
If you kept track of customer addresses in one system and financial information in another, you would traditionally have had to find some way to merge that data constantly to create reports. With event-driven architecture, you always have a conglomeration of all of the most recent data. By listening to the flow of changes to your customers, you always have properly formed and up-to-date data in any application.
This methodology is called event sourcing. It changes the view of data from a static database to a list of changes to the data. Each change is considered an immutable event. The data systems send the events to the data pipeline. All the listening systems are aware of the updates and can choose whether or not to incorporate the events. Instead of viewing data at rest, event sourcing allows businesses to view data in motion.
Put another way, event sourcing is like using a double-entry accounting ledger. In the accounting ledger, you record every transaction. You can tally up these transactions to find the final state of an account. Similarly, event sourcing pipelines have immutable events meaning different applications can take the events according to their needs and derive the states of the data from those events.
Implementing Event Sourcing with Apache Kafka
At Allata, we are always looking at emerging tech to find better ways to serve our customers. We have found that setting up an event sourcing pipeline using Confluent and Apache Kafka is an effective technology strategy for dealing with data and system integration challenges.
Apache Kafka is a framework for stream-processing. You can feed your data events directly into Kafka. Then, any application can read from it. It is like constructing a conveyor belt for your data. You put the data on the conveyor belt, and any application can copy the data from it.
In the Kafka world, data is organized into topics. Topics are data objects inside Kafka. Producers are systems and processes that publish data into Kafka topics. Consumers are systems and processes that subscribe to topics and read data from the Kafka stream.
Kafka offers a way to simplify data synchronization for everyone. Suppose you want to share customer information between various systems. You can use the following steps:
- Create a Kafka topic for customer information.
- Whenever anyone updates a piece of customer information, they publish using the customer topic and include the data source.
- Anyone besides the updater who needs the current state of the customer information can get the transaction events and compute the current state of the data. The transaction event can be anything like a new purchase, an address change, or a financial information update.
The reasons for implementing this event-driven architecture are:
Case Study: Data Spread Thin Across Systems
Allata built an event sourcing solution for one of our clients using the Confluent Platform and Apache Kafka. Their customer data was spread across half a dozen separate systems that would all be updated independently.
The systems held different portions of the customer object like customer information, financial information, shipping locations, event participation, purchased items, etc. They had constant issues with their customer object getting out of sync in their systems like Salesforce, SAP, data lakes, and MySQL. Sometimes shipments were misplaced due to outdated info.
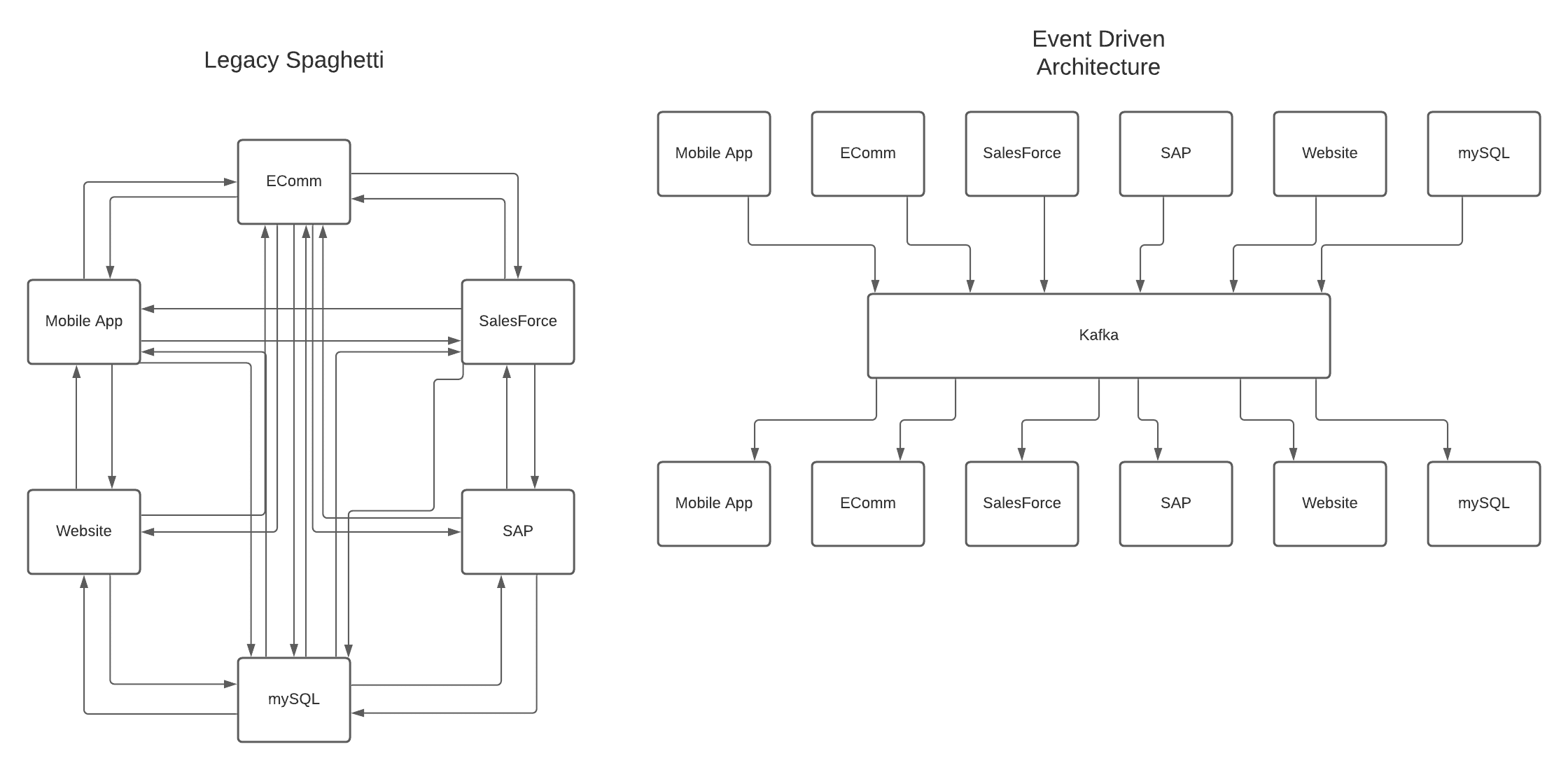
We used Kafka and created a data stream for their customer information. As a result, when the customer data is updated in any system, the other systems that hold overlapping partial data are seamlessly updated. Moreover, any application that purely utilizes this data is always kept perfectly up to date with whatever was most recently published.
Client Takeaway
After we implemented the event-driven architecture, the most significant benefit for the client was that their data is always synchronized across their tertiary systems. When they have a new application that needs access to customer data, our client does not need to go through the arduous and costly process of merging data into a new data lake. They can tie the new application into the Kafka data stream, and the application immediately has access to the most up-to-date customer information.


